

AI-powered research has seven structural weaknesses: choosing information sources, constructing search queries, selecting search engines, fetching web pages, geo-blocking, reading PDFs, and managing tokens. Here’s what I’ve noticed from conducting overseas company investigations.
I once asked ChatGPT to “list 20 food manufacturers in Thailand.” What I got back was a list of well-known companies with English-language websites.
“I could have gotten the same results from a Google search myself,” I thought.
Overseas company research is my job. Using AI as a tool while conducting investigations, I noticed that AI hits the same walls every time, in the same predictable pattern. Let me walk through the seven barriers I’ve encountered.
There Are Barriers at All Seven Stages
When you hand research to AI, problems surface at all seven stages – from choosing information sources to managing tokens.
| # | Research Stage | Where AI Stumbles |
|---|---|---|
| 1 | Where to look (source selection) | Only does web searches. Can’t predict “this data lives in that database” |
| 2 | Search query construction | Doesn’t use AND/OR or phrase search. Doesn’t search in local languages |
| 3 | Search engine selection | Doesn’t use Google. Disadvantaged for Asian languages |
| 4 | Web page retrieval | Can’t read JavaScript-rendered pages. Can’t operate database interfaces |
| 5 | IP-based geo-blocking | Servers are in the US and can’t access locally restricted sites |
| 6 | Document reading | Reads every page from top to bottom. Can’t skim |
| 7 | Token management | Poor allocation – stops right when it matters |
Let me go through each one.
Barrier 1 – AI Doesn’t Know Where the Data Lives
AI starts with a web search no matter what you ask, but much of the data needed for overseas company research can’t be found through web search.
This was the first barrier I noticed.
When asked to “list food manufacturers in Thailand,” I used to start with Google myself. Then one day I discovered that the Thai Department of Industrial Works (DIW) maintains a factory registration database. Search by industry classification code, and you get the complete list of registered factories. The difference was eye-opening.
| What AI Does | What I Usually Do | |
|---|---|---|
| First action | Web search for “Thailand food manufacturer” | Predict “Thai food factory data should be in the DIW database” |
| Information source | Google search results | DIW factory database, searched by industry classification code |
| What you get | 10-20 well-known companies with English websites | Complete list of registered factories matching the code |
| What you miss | Every company without an English website | Registration-based, so coverage is comprehensive |
The same pattern shows up in other investigations. “If a product requires certification, the certification database has a manufacturer list.” “US customs data is searchable on ImportYeti by HS code.” This ability to predict where data lives came from conducting hundreds of investigations.
Here’s what happened when I actually asked ChatGPT and Perplexity.
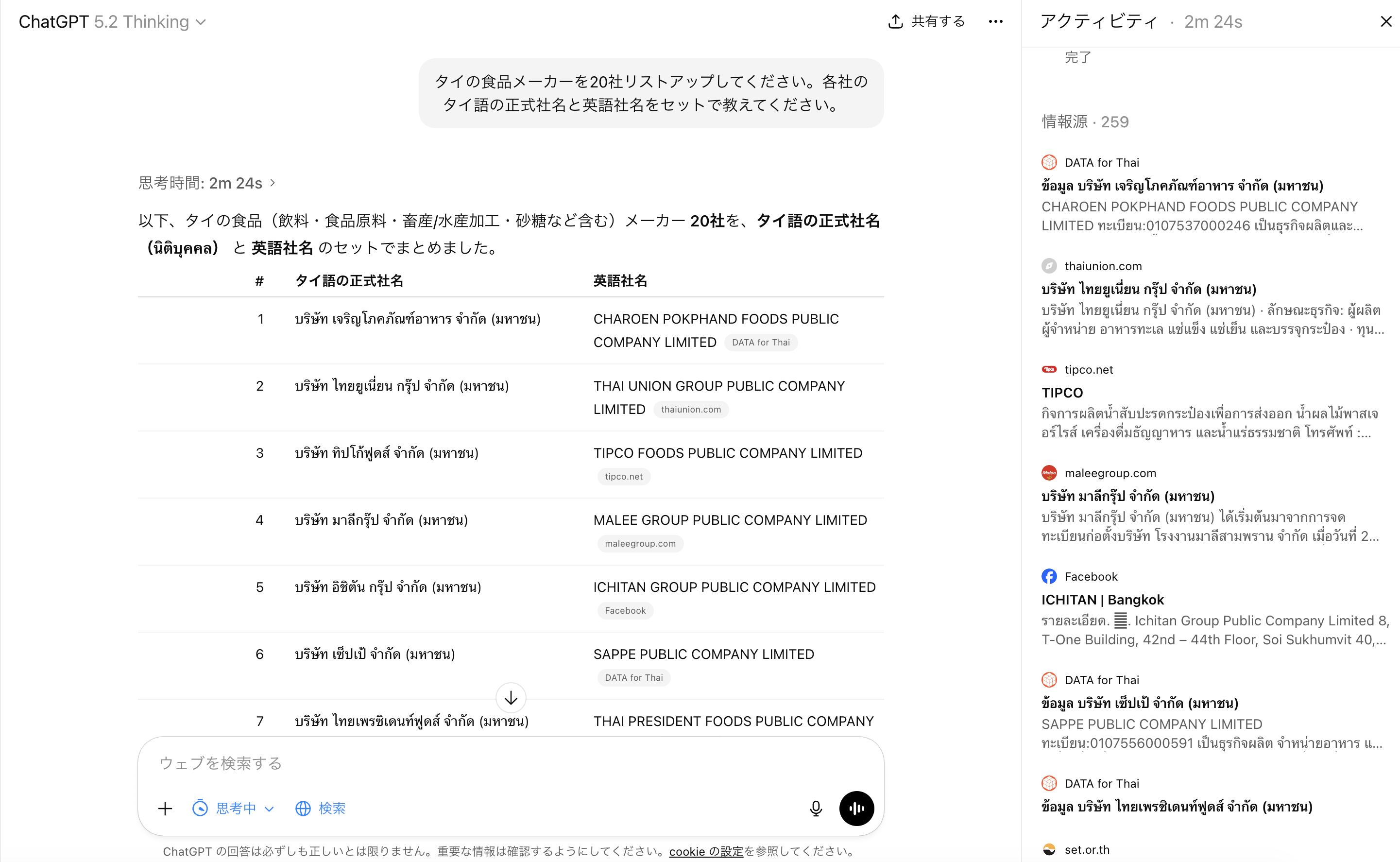

Meanwhile, accessing the DIW database directly with an industry classification code returns data like this.
(Sample entry – Ban Bung Dairy Cooperative, 24/15 Non Chak, Ban Bung District, Chonburi Province. Manufacture of pasteurized butter, processed milk, and yogurt. Machinery: 176.50 HP, Capital: 11.5 million baht, 10 employees.)

Barrier 2 – Search Queries Are Sloppy
AI tends to generate simple English keyword strings as search queries. It doesn’t use AND/OR combinations or phrase search, and it doesn’t search in local languages.
When you ask AI to “research food manufacturers in Thailand,” it starts searching with simple queries like “Thailand food manufacturer” or “Thai food company list.” I would take a more deliberate approach.
| AI’s Search Queries | Queries I Build | |
|---|---|---|
| Language | English only | Search in Thai (“โรงงานอาหาร” = food factory) |
| Structure | String of keywords | Combine conditions with AND/OR |
| Filtering | None | Filter by province, industrial estate, industry code |
| Phrase search | Not used | Wrap in “” for exact match |
For example, searching in Thai for “โรงงานอาหาร” surfaces a large number of local small and medium manufacturers that don’t appear in English-language results. Add a province name – “โรงงานอาหาร ชลบุรี” – and you narrow it to food factories in Chonburi Province.
The quality of your search query changes the number of companies you find by orders of magnitude. AI doesn’t seem to have learned this craft well, and defaults to generic English keywords.
Barrier 3 – The Search Engine Isn’t Google
Most AI tools use a search engine other than Google internally. For Japanese and Asian languages, Google performs significantly better, putting AI-powered search at a disadvantage.
Even if you’ve constructed a local-language query as described in Barrier 2, the engine processing it may be the bottleneck. For English, most search engines deliver comparable results. But for Japanese, Thai, and Vietnamese, the differences become significant.
Consider searching in Thai for “โรงงานอาหาร ชลบุรี” (food factories in Chonburi Province).
| Search Language | Google Search | AI’s Built-in Engine |
|---|---|---|
| English | Comparable results | Comparable results |
| Japanese | Government and industry sites rank high | Accuracy varies |
| Thai | DIW database and local companies rank high | English sites tend to mix in |
ChatGPT, Perplexity, and Copilot use non-Google search engines (Gemini being the exception). Users have no visibility into which engine their AI tool uses. When Asian companies “somehow don’t show up,” the search engine itself is sometimes the reason.
Barrier 4 – AI Can’t Operate Databases
AI can read static web pages, but it can’t fill in forms or fetch JavaScript-rendered pages. Most information sources used in overseas company research hit this barrier.
Here are examples of sources that AI can’t read even when given the URL.
Thai Ministry of Commerce (DBD) – Enter company name in Thai → download financial data
UL Product iQ – Enter category code to find certified companies
National factory registration databases – Specify industry code and region to list factories
All require entering conditions into a browser form to retrieve data.
The fact that data “exists” on the web and the fact that AI can “access” it are two different things.
Barrier 5 – Some Sites Can’t Be Opened from US Servers
ChatGPT, Claude, Perplexity, and other AI tools most likely access the web from servers in the United States. Sites that are only available within the local country are simply unreachable.
Some Thai and Indonesian government websites apply IP-based geo-blocking, allowing access only from domestic IP addresses.
Thai Department of Industrial Works (DIW) – Some search functions are restricted to Thai IPs
Indonesian company registration databases – Some pages are domestic-access only
Chinese corporate credit information sites – CAPTCHAs and connection limits are imposed on overseas access
I live in Thailand, so Thai government sites work fine for me. But as long as AI servers are located in the US, data from these sites is out of reach. AI tools don’t have VPN capabilities to work around these restrictions.
Barrier 6 – AI Can’t Skim a PDF
When you give AI a PDF, it starts reading from page 1. It can’t scan the table of contents and jump to the relevant chapter.
The PDFs I encounter in overseas research commonly exceed 100 pages. Compare how I read versus how AI reads.
How I read – Check the table of contents → open only the relevant chapters → pull out just the tables and charts
How AI reads – Process every page from the beginning → hit the token limit around page 20-30
The data tables in the latter half are never reached. Reading every page is something even I almost never do.
Barrier 7 – Poor Token Allocation Stops Research Mid-Stream
AI has a hard limit on how much information it can process at once (the token limit). The problem isn’t the limit itself – it’s that AI is bad at allocating tokens.
I can glance at 50 search results and decide “only these 5 are worth reading.” AI struggles with this triage, reading results one by one in order. Around the 10th to 20th result, it hits the token limit.
Right when it’s getting close to the core information, it stops and asks “shall I continue?” Deciding where to concentrate tokens is something AI still finds difficult. You asked it to investigate, but it stopped halfway. This is one root cause of the feeling that “AI research is shallow.”
The Core Issue Behind All Seven Barriers Is Research Design
What AI lacks isn’t processing power – it’s the judgment to decide “where to look next.”
The “deep research” features being marketed by AI companies are evolving toward more searches and more pages read. But I think this is just spreading wider, not going deeper.
True depth means following one lead to the next, drilling down through multiple layers.
Discover a company name
→ Check certification DB for model numbers
→ Identify the OEM parent
→ Verify factory operations in local language
This judgment of “where to dig next” is what determines research depth. I leverage AI’s processing speed and multilingual comprehension while keeping a human in charge of source selection, search engine choice, and database access. A tool is only as good as the person using it. That’s what trial and error have taught me.
What Gets Missed When You Treat AI Search Results as “Research Complete”
Asking AI to “look this up” is natural. But treating the results as a finished investigation means gaps will remain.
| # | Barrier | What Happens as a Result |
|---|---|---|
| 1 | Source selection | Every company not on the open web is missed |
| 2 | Search query construction | Information in local languages is entirely missed |
| 3 | Search engine | Search accuracy drops for Asian languages |
| 4 | Page retrieval constraints | Government and certification database data can’t be extracted |
| 5 | Geo-blocking | Locally restricted sites are inaccessible |
| 6 | Document reading | 100-page reports can’t be read through |
| 7 | Token allocation | Research stops right when it matters |
AI has the power to gather information broadly. Add “which databases to use,” “which languages to search in,” and “how to interpret the data” – and the depth of your research changes.
About the Author
Takashi Kinoshita – CEO, Taitonmai Co., Ltd.
Graduate degree from a national university
8 years in procurement at a major Japanese electronics manufacturer
Including 2 years stationed at the company’s Thailand factory as Procurement Section Manager, managing local staff as the sole Japanese manager
Experienced procurement operations in English, Chinese, and Thai
After founding Taitonmai, has conducted corporate investigations spanning 80+ countries and 10,000+ companies
