
生成AIの調査には7つの構造的な弱点があります。情報源の選び方、検索クエリの組み立て、検索エンジン、Webページの取得、地域ブロック、PDFの読み方、トークンの管理。海外企業調査の現場で気づいたことを書いてみます。
ChatGPTに「タイの食品メーカーを20社リストアップして」と頼んでみました。返ってきたのは英語サイトのある有名企業ばかり。
「これ、自分で日本語でGoogle検索しても同じだな」と思いました。
海外企業の調査が自分の仕事です。AIを使いながら調査してきた中で、AIが決まったパターンで止まることに気づきました。7つの壁を整理してみます。
調査の全工程で問題が起きる
生成AIに調査を任せると、情報源の選定からトークンの管理まで7つの段階すべてで壁にぶつかります。
| # | 調査の段階 | AIがつまずくポイント |
|---|---|---|
| 1 | どこを調べるか(情報源の選定) | Web検索しかしない。「あのDBにデータがある」と推測できない |
| 2 | 検索クエリの組み立て | AND/ORやフレーズ検索を使わない。現地語で検索しない |
| 3 | 検索エンジンの選択 | Googleを使っていない。アジア言語で不利になる |
| 4 | Webページの取得 | JavaScriptのページが読めない。DB操作ができない |
| 5 | IPアドレスの地域ブロック | サーバーが米国にあり、現地限定サイトにアクセスできない |
| 6 | PDFの読み方 | 全ページ上から順に読む。拾い読みができない |
| 7 | トークンの管理 | 配分が下手で、肝心なところで止まる |
順番に書いていきます。
壁1 — AIは「どこにデータがあるか」を知らない
生成AIはどんな質問にもまずWeb検索から始めます。しかし海外企業調査で本当に必要なデータの多くは、Web検索では見つかりません。
自分が最初に気づいた壁です。
「タイの食品メーカーをリストアップして」と言われたとき、自分も昔はGoogle検索から始めていました。ある時、タイ工業省工場局(DIW)に工場登録データベースがあることを知ります。業種コードで検索すると、登録工場が全件出てくる。差は歴然でした。
| AIがやること | 自分がよくやること | |
|---|---|---|
| 最初の行動 | 「Thailand food manufacturer」でWeb検索 | 「タイの食品工場データはDIWにあるはず」と推測 |
| 情報源 | Google検索の結果 | DIWの工場DBに業種コードでアクセス |
| 得られる結果 | 英語サイトのある有名企業10〜20社 | 該当する登録工場の全件リスト |
| 漏れ | 英語サイトを持たない企業が全部漏れる | 登録ベースなので網羅性が高い |
ほかにも同じパターンがあります。「認証が必要な製品なら認証DBにメーカー一覧がある」「米国の通関データはImportYetiでHSコード検索できる」。情報源を推測する力は、何百件も調査する中で少しずつ身についたものです。
実際にChatGPTとPerplexityに聞いてみた結果がこちらです。
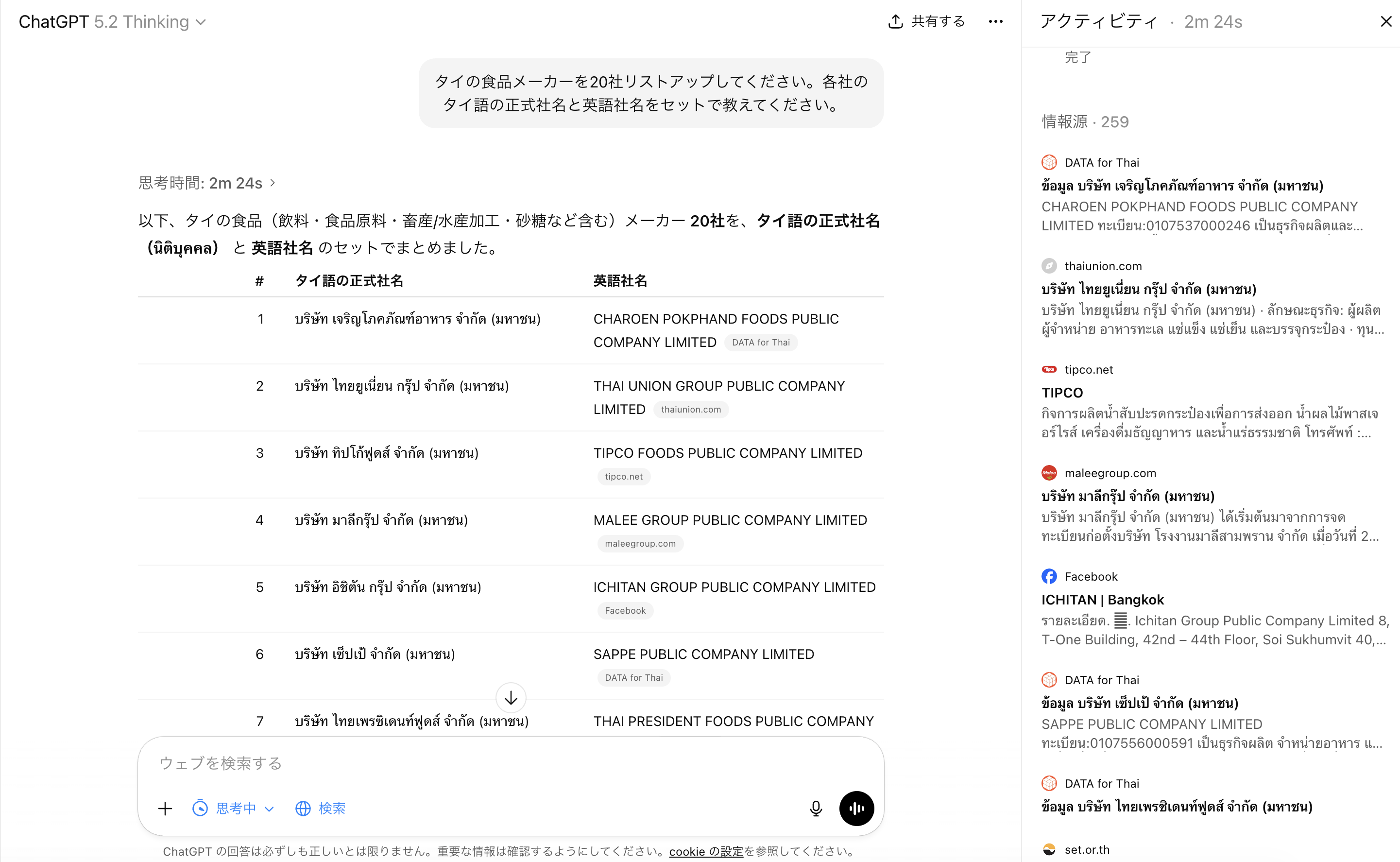

一方、タイの工場局(DIW)のデータベースに業種コードでアクセスすると、こういうデータが取れます。
(記載内容 — バーンブン酪農協同組合、チョンブリ県バーンブン郡ノンチャーク地区 24/15、パスチャライズドバター、加工乳、ヨーグルトの製造、機械176.50馬力、資本金1,150万バーツ、従業員10名)

壁2 — 検索クエリの組み立てが雑
AIが生成する検索クエリは単純な英語キーワードの羅列になりがちです。AND/ORの組み合わせやフレーズ検索を使わず、現地語でも検索しません。
「タイの食品メーカーを調べて」と頼むと、AIは「Thailand food manufacturer」や「Thai food company list」のような単純なクエリで検索を始めます。自分なら、もう少し工夫します。
| AIの検索クエリ | 自分が組み立てるクエリ | |
|---|---|---|
| 言語 | 英語のみ | タイ語で検索する(「โรงงานอาหาร」= 食品工場) |
| 構造 | 単語の羅列 | AND/ORで条件を組み合わせる |
| 絞り込み | なし | 県名、工業団地名、業種コードで絞る |
| フレーズ検索 | 使わない | ""で囲んで完全一致を指定する |
たとえばタイ語で「โรงงานอาหาร」と検索すると、英語では出てこない地場の中小メーカーが大量に見つかります。さらに県名を加えて「โรงงานอาหาร ชลบุรี」とすれば、チョンブリ県の食品工場に絞れる。
検索クエリの質で、見つかる企業の数が桁違いに変わります。 AIはこの組み立てをあまり学習していないようで、どうしても英語の一般的なキーワードに頼ってしまいます。
壁3 — 検索エンジンがGoogleではない
生成AIの多くは内部でGoogleではない検索エンジンを使っています。日本語やアジア圏の言語ではGoogleの方が強いため、AI経由の検索は不利になりがちです。
壁2でせっかく現地語のクエリを組み立てたとしても、それを処理するエンジン側に問題があります。英語なら、どの検索エンジンでも大差ありません。しかし日本語、タイ語、ベトナム語などアジアの言語では、検索結果に明確な差が出ます。
たとえばタイ語で「โรงงานอาหาร ชลบุรี」(チョンブリ県の食品工場)と検索した場合。
| 検索言語 | Google検索 | AI内蔵のエンジン |
|---|---|---|
| 英語 | 同等の結果 | 同等の結果 |
| 日本語 | 官公庁・業界サイトが上位 | 精度にばらつきがある |
| タイ語 | 工場局DBや地場企業が上位 | 英語サイトが混ざりやすい |
ChatGPT、Perplexity、CopilotなどはGoogle以外の検索エンジンを使っています(Geminiを除く)。ユーザーからは何のエンジンが使われているか見えません。「なぜかアジアの企業がうまく見つからない」という場合、ここが原因のことがあります。
壁4 — データベースの操作ができない
AIは静的なWebページは読めますが、フォーム入力やJavaScriptページの取得ができません。海外企業調査で使う情報源の大半が、この壁に引っかかります。
URLを渡しても中身が読めないものの例です。
- タイ商務省DBD — タイ語で社名を入力 → 財務データをダウンロード
- UL Product iQ — カテゴリコードで認証企業を検索
- 各国の工場登録DB — 業種コード・地域を指定して工場一覧を取得
いずれも、ブラウザ上でフォームに条件を入力しないとデータが出てきません。
Webにデータが「ある」ことと、AIがそのデータを「取り出せる」ことは別の話です。
壁5 — 米国サーバーからでは開けないサイトがある
ChatGPT、Claude、Perplexityなどの生成AIは、おそらく米国のサーバーからWebにアクセスしています。現地国内からしか開けないサイトには、そもそもたどり着けません。
タイやインドネシアの政府サイトには、IPアドレスによる地域ブロックをかけているものがあります。自国内からのアクセスだけを許可する仕組みです。
- タイ工場局(DIW) — 一部の検索機能はタイ国内IPのみ
- インドネシアの企業登録DB — 国内アクセス限定のページがある
- 中国の企業信用情報サイト — 海外からはCAPTCHAや接続制限がかかる
自分はタイに住んでいるのでタイの政府サイトは問題なく使えます。しかしAIのサーバーが米国にある以上、こうしたサイトのデータは取得できません。VPNを使うような回避手段も、AIには備わっていないのが現状です。
壁6 — PDFの拾い読みができない
AIにPDFを読ませると1ページ目から全文を読み始めます。目次を見て必要な章だけ開く、という判断ができません。
海外調査のPDFは100ページ超が普通です。自分がPDFを読むときと、AIの読み方を比べてみます。
- 自分の読み方 — 目次を見る → 必要な章だけ開く → 表やグラフのデータだけ拾う
- AIの読み方 — 1ページ目から順に全文を処理 → 20〜30ページでトークン上限に達する
肝心のデータが載っている後半にたどり着けないまま終わることが珍しくありません。全ページ読むことは、自分もまずやらない作業です。
壁7 — トークンの配分が下手で途中で止まる
AIは一度に処理できる情報量(トークン数)に上限があります。問題は上限そのものではなく、トークンの配分が下手なことです。
自分なら50件の検索結果をざっと眺めて「この5件だけ読もう」と判断できます。AIはこの取捨選択が苦手で、見つけた情報を1つずつ律儀に読んでいく。10〜20件ほど処理したところでトークン上限に達してしまいます。
ようやく核心に近づいたところで「続けますか?」と止まる。 どこにトークンを集中させるかの判断が、AIにはまだ難しいようです。調べてほしいのに途中で止まる。「AIの調査は浅い」と感じる原因の一つではないでしょうか。
7つの壁に共通する本質は「調査の設計力」
AIに足りないのは処理能力ではなく、「次にどこを調べるか」という判断力です。
最近の「ディープリサーチ」機能は、検索回数とページ数を増やす方向に進化しています。しかし、これは横に広げているだけではないでしょうか。
本当の深さとは、1つの手がかりから次を辿って掘り下げること。たとえばこんな流れです。
- 企業名を発見
- → 認証DBで型番を確認
- → OEM元を特定
- → 現地語で工場の稼働状況を裏取り
この「次にどこを掘るか」の判断が、調査の深さを決めます。自分はAIの処理速度と多言語理解を活かしつつ、情報源の選定・検索エンジンの使い分け・DBの操作は人間がリードしています。道具は使い方次第。試行錯誤で実感していることです。
AIの検索結果だけで「調査完了」にすると何が漏れるか
AIに「調べて」と頼むのは自然なことです。ただ、返ってきた結果をそのまま最終版にすると、見落としが出ます。
| # | 壁 | 結果として起きること |
|---|---|---|
| 1 | 情報源の選び方 | Web検索に出ない企業が全部漏れる |
| 2 | 検索クエリの組み立て | 現地語の情報が丸ごと抜け落ちる |
| 3 | 検索エンジン | アジア言語の検索精度が落ちる |
| 4 | ページ取得の制約 | 政府DB・認証DBのデータを取り出せない |
| 5 | 地域ブロック | 現地限定サイトにアクセスできない |
| 6 | 文書の読み方 | 100ページのレポートを読み通せない |
| 7 | トークンの配分 | 肝心なところで調査が止まる |
AIの広く集める力に、「どのDBを使うか」「どの言語で検索するか」「データをどう読み解くか」を加えると、調査の深さが変わります。
海外市場調査・企業リストアップ
調査のご相談は無料です。お気軽にお問い合わせください。